Talks
Some data science talks I've given
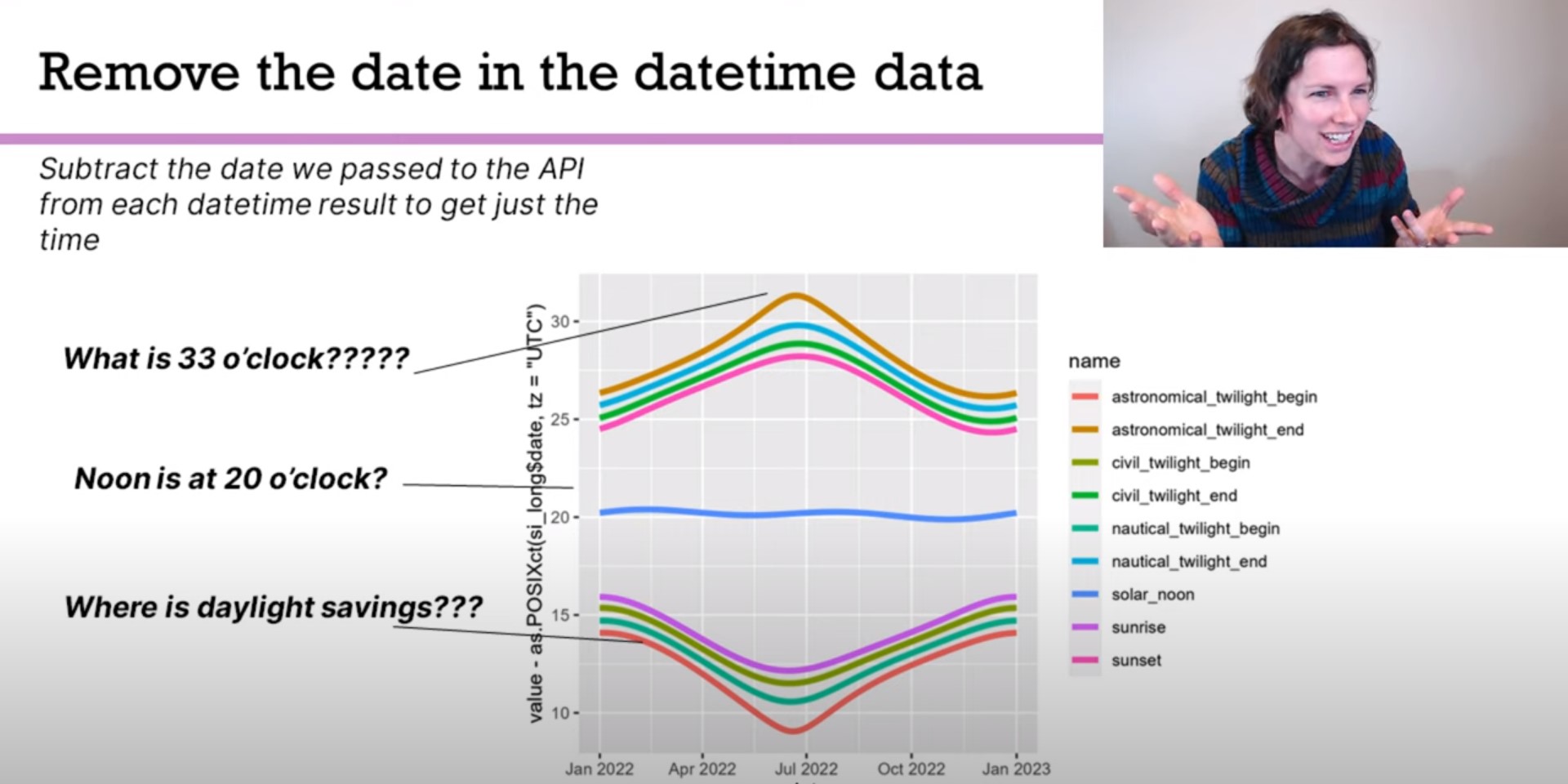
Alaska challenged my preconceived notions of storing sunset data
Normconf 2022 | December 15, 2022
Once I had a simple idea to make pretty plots of when the sun rises and sets in different cities. Unfortunately, this turned out to be a massive headache because storing times is way more complex than you always think it is. In this talk I will talk about how to work through the many datetime challenges with Fairbanks Alaska, the city where the sun can set earlier than it rises.
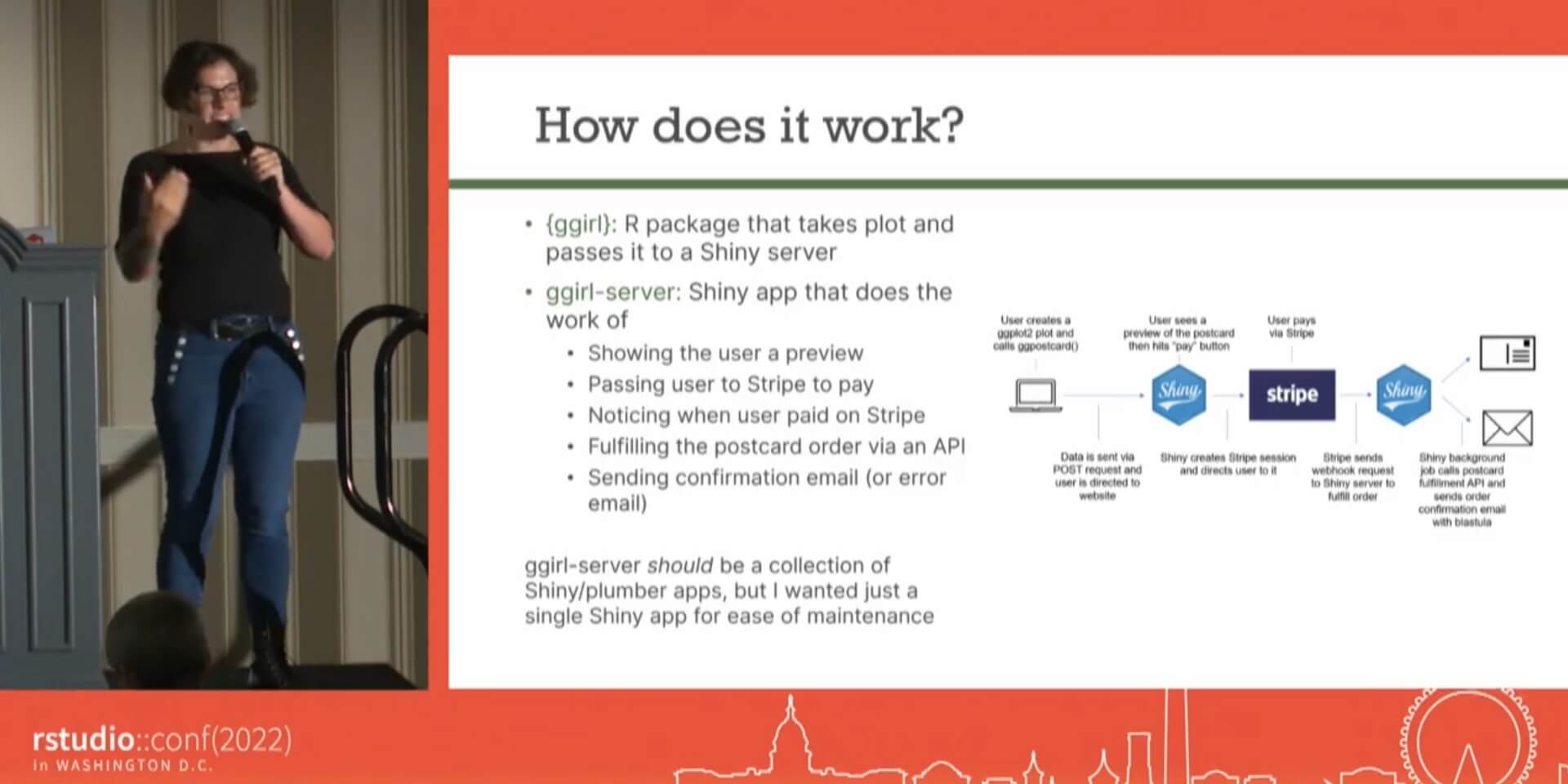
I made an entire e-commerce platform on Shiny
Rstudio::conf(2022) | July 28, 2022
E-commerce requires passing data between many components like managing a shopping cart, taking payment, fulfilling orders, and sending emails. I've successfully created a full e-commerce platform entirely in R for a quirky side project. The R package ggirl lets users order ggplot2 plots as postcards and more via R functions. Those R functions pass data to a separate Shiny app, which then passes data other services like Stripe payment APIs and printing APIs. In this talk I will walk through how to use packages like httr, callr, and brochure to have your Shiny apps call external services and do many tasks in parallel. You’ll leave the talk with more ways to use Shiny than dashboards plus the knowledge to monetize your existing dashboards!

R in Parallel
Saturn Cloud Webinar | July 14, 2022
When using R you sometimes have situations where your code could run much faster if it was parallelized. Having code run concurrently can give a great speed boost, but learning how to run R code in parallel can seem like steep learning curve. In this webinar I'll give a straight-forward introduction to running concurrent code with R packages future, furrr, and callr. I'll cover how to spawn concurrent tasks, iterate over lists in parallel, and integrate parallelization into your existing R workflows. By the end of the webinar you'll be ready to add concurrency to your R code!

Docker for Data Scientists
Saturn Cloud Webinar | June 1, 2022
As a data scientist you've probably heard people use the term "Docker" before, but for many data scientists it remains a mystery. But in fact not only is Docker helpful a great tool for data scientists, it's also something you can get started with in under and hour. In this talk you'll learn about how you can use Docker to make your analyses more reproducible, deploy code into production, and manage complex systems. No pre-requisite knowledge of Docker required!
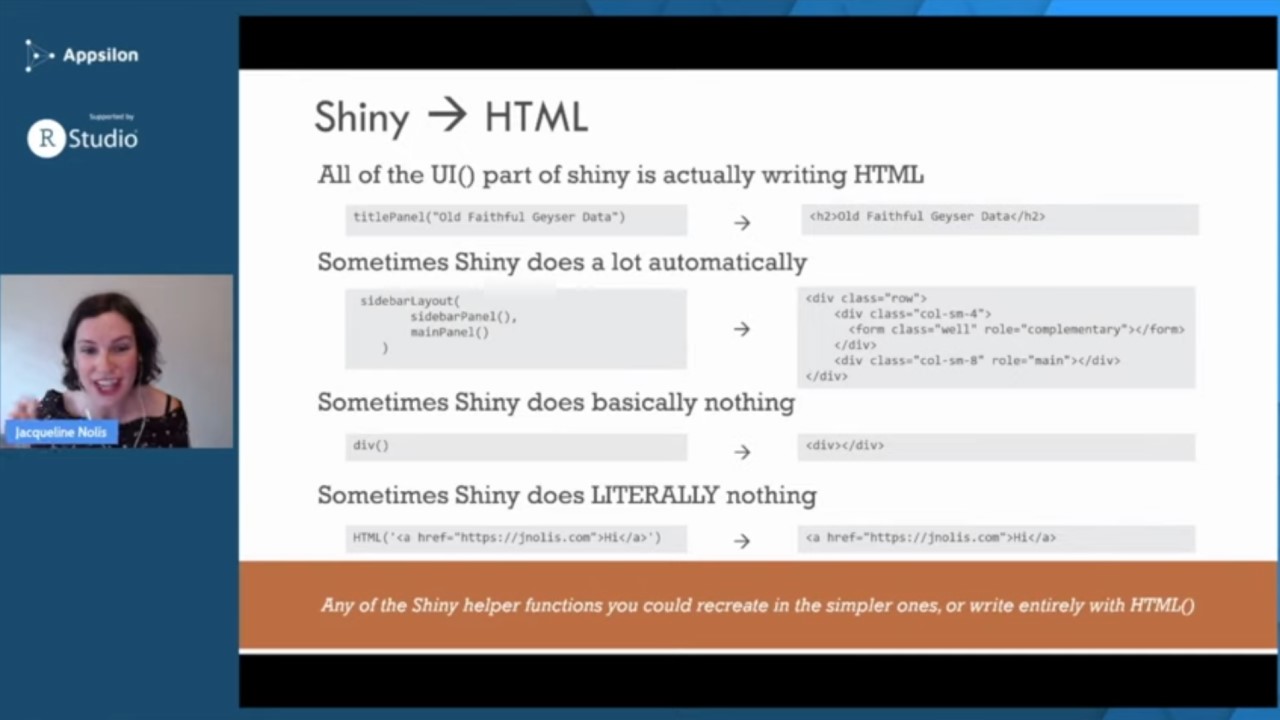
How Shiny taught me web development
Shiny Conf 2022 | April 28, 2022
Over the course of my career I've gone from knowing nothing about web development to having it be most of my job--largely thanks to the help of Shiny! Like one of those cooking recipe blog posts that spends half the page talking about the author's past and then provides you with a practical recipe, this talk will cover how I've used Shiny throughout my job then will present practical Shiny tips. I'll discuss my past of making complex Shiny dashboards powering analytics platforms, and using Shiny to make quick machine learning POCs for stakeholders. I'll also talk about how you can make your shiny apps better with Bootstrap, CSS, and more.

Putting R into Production
Saturn Cloud Webinar | February 3, 2022
Once you've written R code you like, you may want to have others use it, like passing their data to your trained ML model. Creating an API around your work is a great way to do this, and the R package plumber has everything you need to do so. In this talk, we'll go through the basics of developing an API in R, how to use Saturn Cloud Deployments to host your API so anyone can use it, and best practices for creating APIs in R. The talk will also cover the steps to make the code ready for enterprise scale.

Intro to Neural Networks in R
Saturn Cloud Webinar | January 13, 2022
Thanks to packages like Keras, you can get started with neural networks with only a few lines of R code. Once you understand the basic concepts, you will be able to use deep learning to make AI-generated humorous content! In this talk, I give an introduction to deep learning (including on a GPU) by showing how you can use it to make a model that generates weird pet names.
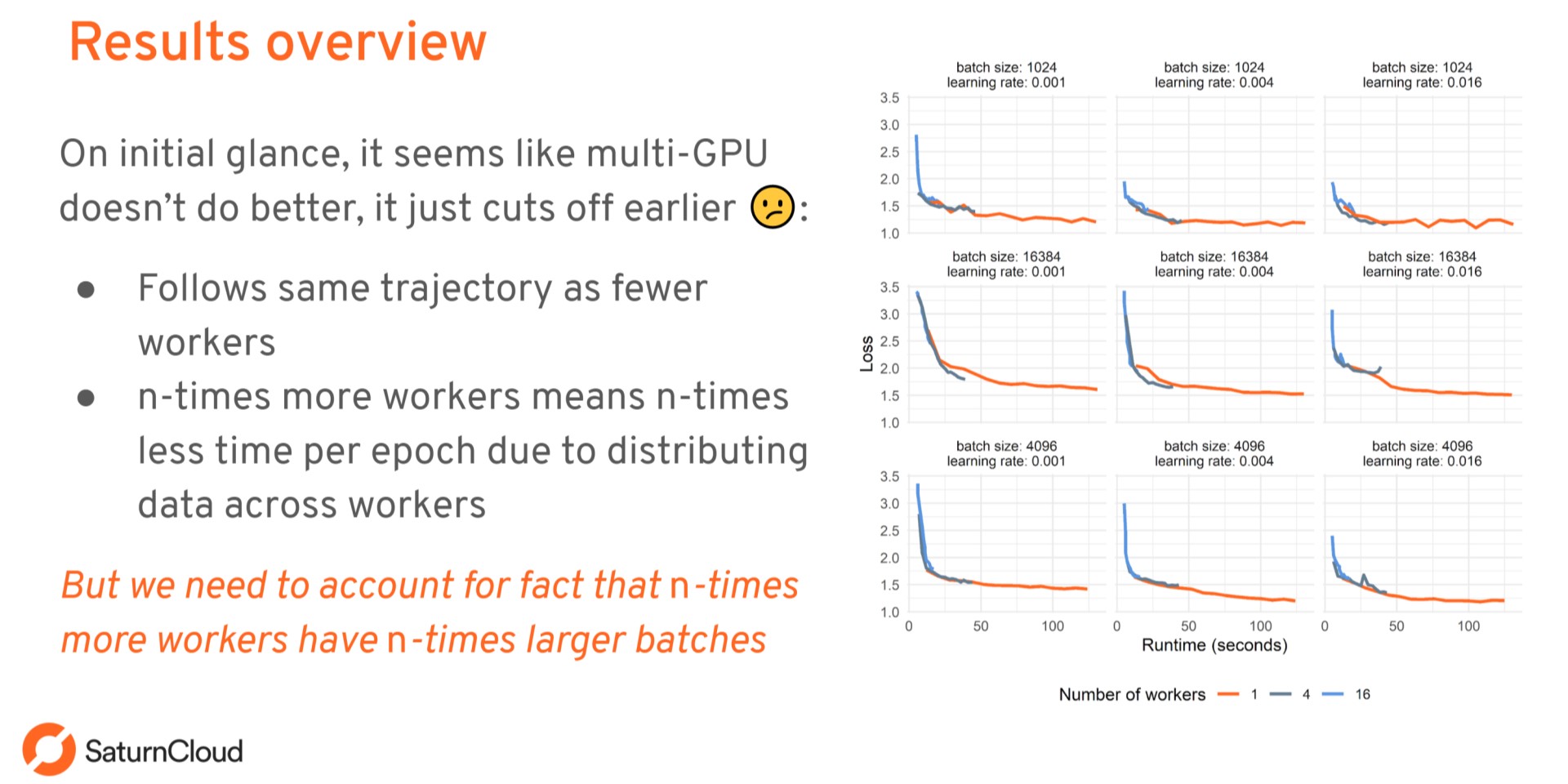
Using Dask and Many GPUs to Train a Neural Network with PyTorch
Dask Distributed Summit 2021 | May 16, 2021
I took a neural network I had trained on a single CPU to generate pet names and tried retraining it with tons of connected GPUs using Dask, PyTorch, and the package dask-pytorch-ddp. I learned a lot about when is the right time to use multiple GPUs and what the pitfalls can be. In this talk I discussed what these lessons mean for training with GPUs and Dask.

What I Learned from Porting my Viral Website from .NET to shiny
Recorded at NY R Conference 2020 | August 14, 2020
In 2016 I created Tweet Mashup, a website that lets you combine the tweets of two different people. After spending a year making it in .NET, when I launched the site it became an immediate sensation and was mentioned in places like the Verge. Years later, I was getting more and more frustrated maintaining the F# code and decided to see if I could recreate it in Shiny. Doing so would require having Shiny integrate with the Twitter API in ways that hadn’t be done by anyone before. Could I pull it off? Come to this talk to find out!

We’re hitting R a million times a day so we made a talk about it
Heather Nolis and Jacqueline Nolis | Rstudio::conf(2020) | January 30, 2020
Often reserved for Elite Engineers, production can be a perilous place for R users - but never fear! For the past year, we at T-Mobile have been sludging through production outages, nation-wide product launches, and all of the muck that floods from R models being hit over a million times every day. From “we’re strictly a java shop” to a devops team that proudly states “we support Java, node, and R,” this talk will cover the technical hiccups, interdisciplinary communication struggles, and an open-source R package {loadtest} that’s changed the way our team views performance testing. You too can dazzle your enterprise with the power of R.

When data science projects fail
PyData Ann Arbor | August 14, 2019
Everyone loves talking about successes, but data science projects fail all the time. Datasets don’t end up having signals, the work takes far longer than expected, and products end up missing the mark. In this recorded talk I examine the key themes that show up in projects that fail and how data scientists can spot them coming. To highlight these themes I use examples from the many failed data science projects that I have been personally responsible for.

You're not paid to model
Metis Demystifying Data Science 2019 | July 30, 2019
Everyone loves talking about successes, but data science projects fail all the time. Datasets don’t end up having signals, the work takes far longer than expected, and products end up missing the mark. In this recorded talk I examine the key themes that show up in projects that fail and how data scientists can spot them coming. To highlight these themes I use examples from the many failed data science projects that I have been personally responsible for.
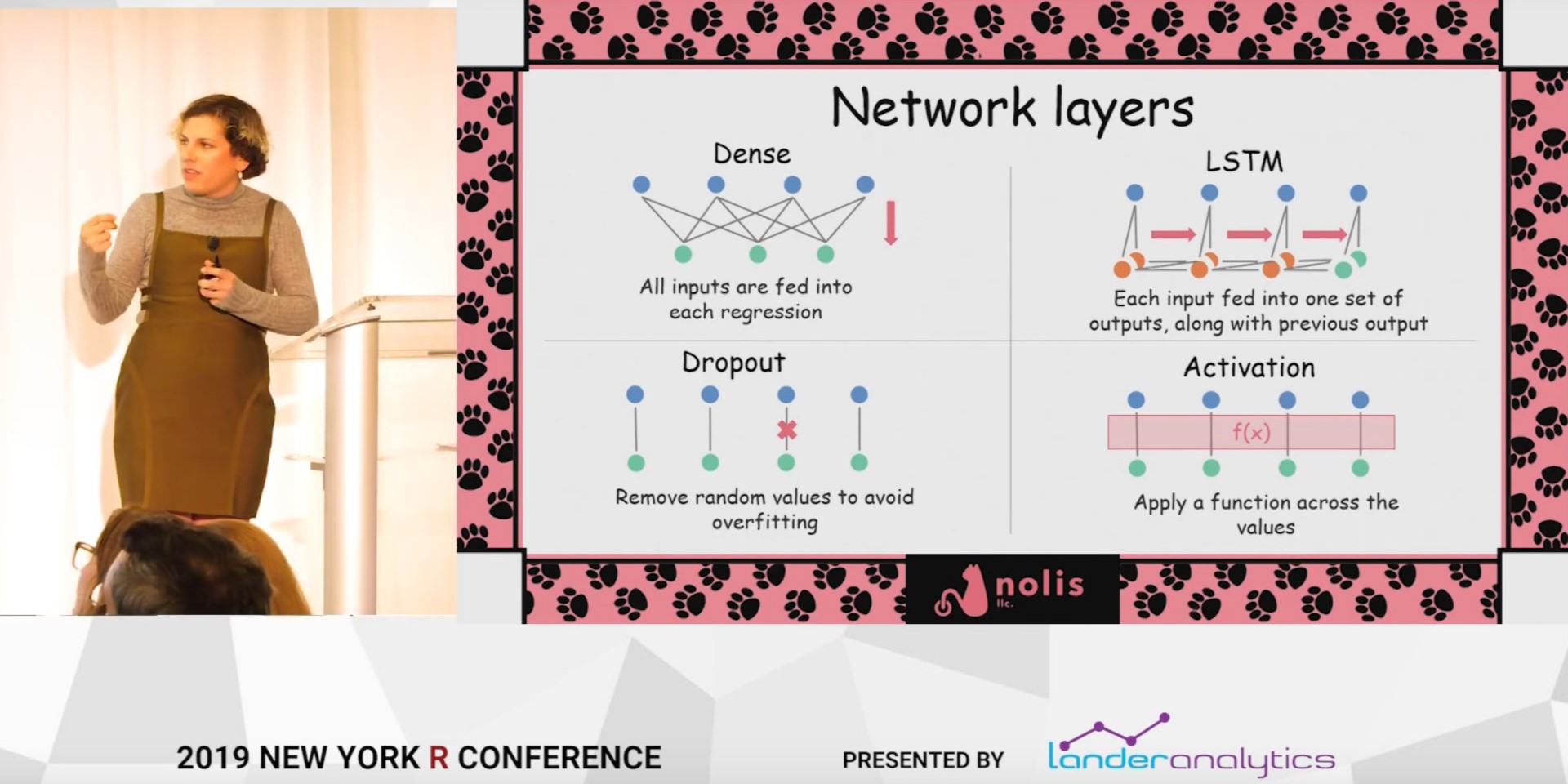
Deep learning isn't hard, I promise
New York R Conference 2019 | May 9, 2019
Deep learning sounds complicated and difficult, but it’s really not. Thanks to packages like Keras, you can get started with only a few lines of R code. Once you understand the basic concepts, you will able to use deep learning to make AI-generated humorous content! In this talk I give an introduction to deep learning by showing how you can use it to make a model that generates weird pet names like: Shurper, Tunkin Pike, and Jack Odins. If you understand how to make a linear regression in R, you can understand how to create fun deep learning projects.

Spanking and Spreadsheets: Data-driven Sex Journalism
Heather Nolis and Jacqueline Nolis | csv,conf,v4 | May 7, 2019
When we saw that the Stranger, Seattle’s alternative newspaper, was running a survey on kinks and sexual preferences, we knew we had to get our hands on the data. We convinced the that using machine learning methods on the responses would be a good idea, and then we quickly set out to analyzing them. In this talk we will cover how we made sense of the lewd data, the statistical methods we used (and failures we produced), as well as the final results that ended up in our feature article: “There Are Four Kinds of Sex Partners (which one are you).”

Push straight to prod: API development with R and Tensorflow
Heather Nolis and Jacqueline Nolis | Rstudio::conf(2019) | January 24, 2019
When tasked with creating the first customer-facing machine learning model at T-Mobile, we were faced with a conundrum. We had been told time and time again to deploy machine learning models in production you had to use Python, but our very best data scientists were fluent in building neural networks in R with Keras and TensorFlow. Determined to avoid double work, we decided to use R in production for our machine learning models. In this talk, we'll walk through how to deploy R models as container-based APIs, the struggles and triumphs we've had using R in production, and how you can design your teams to optimize for this sort of innovation.