rstudio::conf 2019 takeaways
Serious Shiny, R in production, and data science skill growth
rstudio::conf 2019 was a whirlwind conference in Austin, covering a wide range of topics around R and RStudio products. It was a great conference and I had a blast, so now that it’s over and my adrenaline rush is calming I am doing a post-mortem. As an attendee I found that three themes were showing up over and over throughout the event, which sheds some light on where the R community may be heading. A write-up seemed like a good way to not forget them, and if you were unable to attend hopefully this helps with the FOMO!
Theme 1: Shiny is a Serious Product
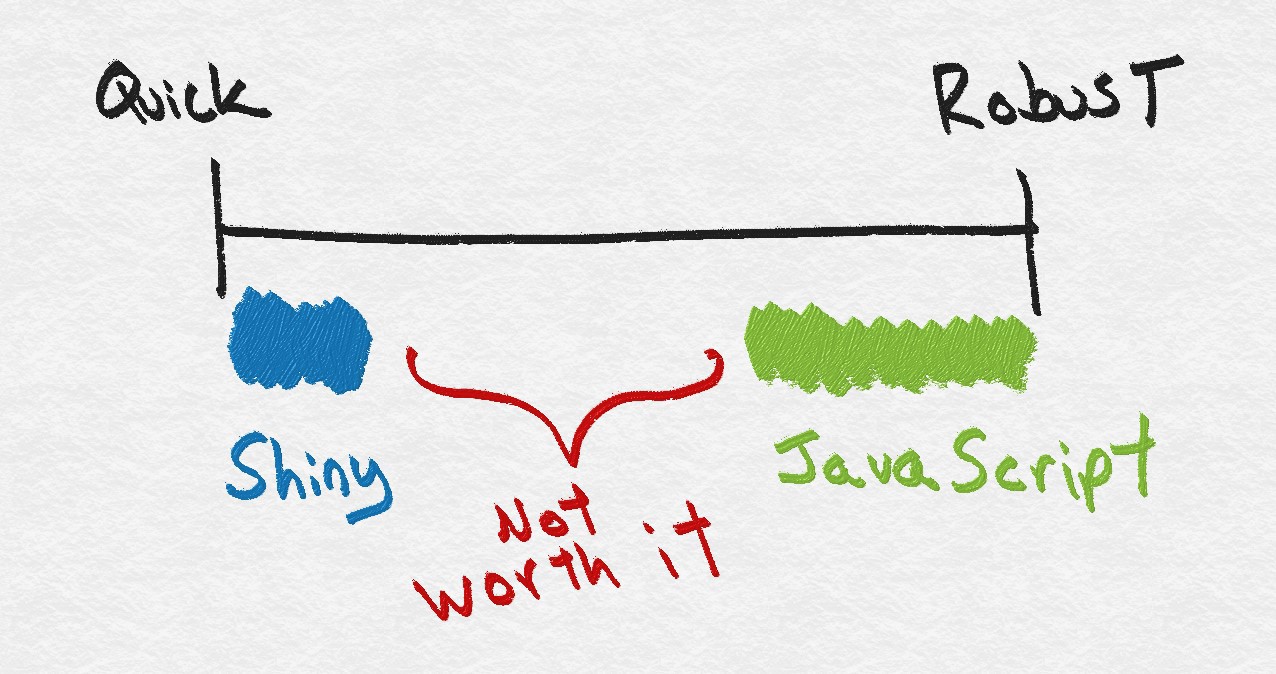
Years ago when I was first exposed to Shiny, the R package that lets you make interactive visualizations, it seemed like powerful tool but enormously fickle. Sure you could take your analysis and add sliders and drop downs to it, but it would take a lot of work before it was fully ready. Further, if you wanted to show it to someone else you had to bring your laptop to them. Every time you made changes to the underlying analysis you hoped that didn’t break your Shiny app. If you wanted something quick and simple Shiny was great, but if you wanted something extremely stable, elegant, or robust you were better off with recoding your work in JavaScript:
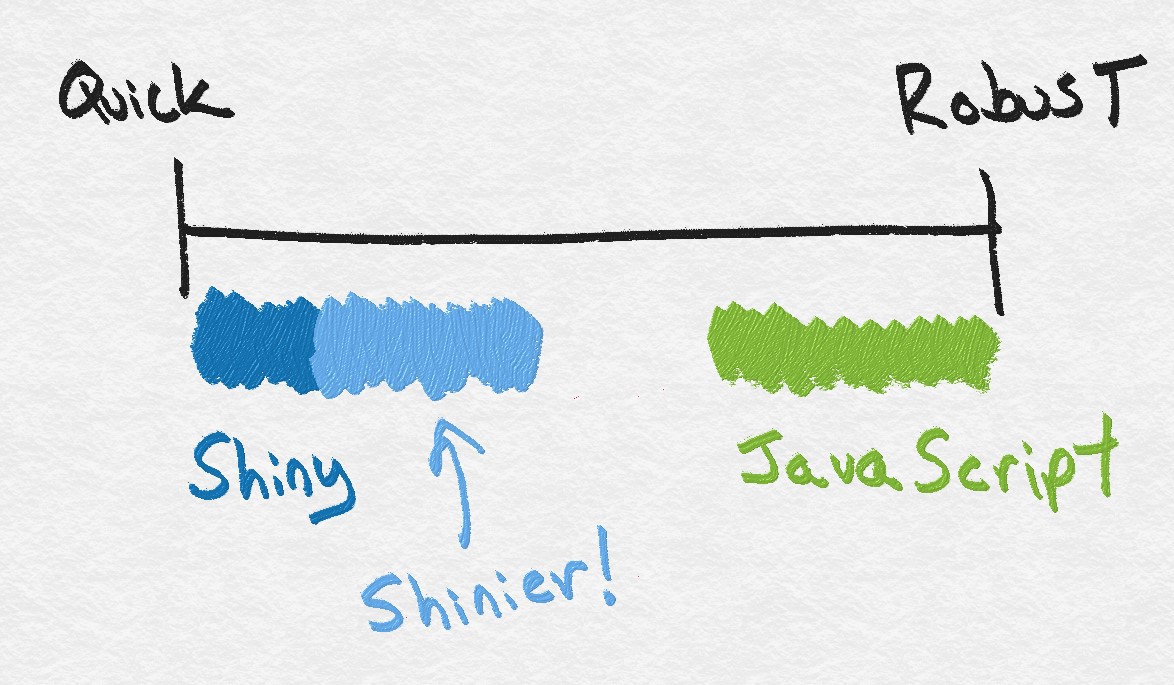
Today, Shiny has come a long way and there are many more situations where it makes sense to use Shiny:
Some of the really helpful improvements to Shiny and new tooling I saw were:
-
shinytest - This R library lets you write the equivalent of unit tests for your apps. You can make a recording of using the app, and then the package will alert you if changes to the R code make the app unexpectedly change.
-
shinyloadtest - Once your app is stable you’ll want to make sure it won’t crash if multiple people use it at once. shinyloadtest is a Java (Java?? ≡ƒñö) program that hits your shiny app with multiple users at once and measures performance degradation.
-
renderCachedPlot - While renderPlot is the typical way of showing a plot in Shiny, it has to redraw the entire image even if the user has selected the same input before. renderCachedPlot speeds this up by keeping a record of older plots.
-
RStudio Connect - This is RStudio’s new enterprise product, which lets data scientists publish their Shiny apps to an internal server at a push of a button.
As for good Shiny use cases, Emily Robinson gave a talk about how she used Shiny to develop the A/B test reporting suite at DataCamp. With Shiny, she was able to create the tools herself instead of having to rely on engineers. Nic Crane presented a Shiny app she worked on for the 100,000 genomes project, which was bursting with functionality and cool HTML widgets.
Theme 2: R in Production
The opening keynote of rstudio::conf heavily featured the idea of “R in production.” For RStudio, that meant using RStudio Connect to have Shiny apps and Rmarkdown reports that are always up and available for users throughout the company to view. RStudio seemed to be focusing on having R be simpler to share internally within a company, as opposed to say, generating a PDF that gets emailed once and lost forever.
R in production can also be about creating APIs as software engineers opt to do. Other talks in the conference covered using the R package Plumber to use R as a web service to host a RESTful APIs. The plumber package featured in a talk on democratizing R by James Blair, it showed up in my Shiny in Production workshop on how to move code out of Shiny, and of course it was a key player in the talk Heather Nolis and I gave on R in Production at T-Mobile. In our talk we covered how we use R to power neural networks that do natural language processing every time a T-Mobile customer send a text message to a customer care representative. While at T-Mobile we use Docker containers to deploy our R code as a microservice, this isn’t the best route for everyone. For the use case of running APIs RStudio again suggests its RStudio Connect product.
 I refuse not to shamelessly share this picture of me and Heather drawn by Brooke Watson
I refuse not to shamelessly share this picture of me and Heather drawn by Brooke Watson
Other things discussed to make R ready for production were the new pkg function, presented by Gabor Csardi and plenty of dependency functionality presented in a talk from Jim Hester. Together those to talks gave a lot of tools for R users who struggle to maintain which versions of packages their code is using. This is really important if your R code is going to be run by other people, or have to be run in the future when the dependencies may have been updated. Another solution to dependency madness is the new RStudio Package Manager, which basically lets your company have its own mini-CRAN that you can put internal packages onto.
Theme 3: Data Science Skill Growth
A lot of the talks had nothing to do with R itself; they focused on how people can grow their own skills in data science or the skills within their organization. Data science is a young enough field that we don’t have more standardized thinking on how to organize and grow compared to fields like software engineering ' not that they have a particularly strong grasp of it either.
Felienne gave an amazing keynote on how to think about teaching the skills of programming and supporting a community. Programming is traditionally taught as in a “explore puzzles on your own to learn” way which science shows is awful. When teaching people to program you should clearly explain the topics and give structured ways to practice, just like we do with every other topic in schools.
Other noteworthy talks on this topic I saw include one from Caitlin Hudon, who did the bold thing I love where she actually revealed mistakes she has made while a data scientist. Understanding the ways that successful people have messed up is a great way to learn, and I have found the data science community is unusually good at it. Angela Bassa gave a great talk on how to think about data science as a team sport and organizational design.
 This question always plagued me but I love Angela’s answer: “don’t worry about it."
This question always plagued me but I love Angela’s answer: “don’t worry about it."
David Robinson gave the last keynote of the conference which covered how to help contribute through the data science community with tweets, blog posts, conference talks, and books (in that order). Contributing to the community with things like blogging is a great way to help other people grow and boost your career (Except this blog post isn’t just to boost my career of course ≡ƒÿà≡ƒÿà≡ƒÿà). As a person who does all these activities A+++++ would recommend.
Wrapping it up
There were other great talks that didn’t fit into those themes, like:
-
Brooke Watson’s talk on how the ACLU uses R to understand data on separated asylum-seeking families,
-
Rich Iannone giving a standing room only presentation on the gt package for making elegant HTML tables in Rmarkdown or Shiny, and
-
Sigrid Keydana’s presentation on using eager execution in TensorFlow to make more non-standard neural networks.
Karl Broman did a great job at making one GitHub repository that has all the slides (and soon RStudio will release the videos of them), so check them out yourself!
Love that @hadleywickham shared the Pac-Man rule with everyone - to make #RStudioConf (even) more welcoming, when you’re talking in a group always leave space for someone else to join the conversation pic.twitter.com/tnzEJ5cOxL
— Emily Robinson (@robinson_es) January 17, 2019
Overall rstudio::conf was a fantastic time where lots of solid material was presented. But that paled in comparison to how welcoming everyone was! In the first five minutes of the first day Hadley Wickham mentioned the Pacman rule: make every conversation open to new people. I couldn’t believe how much that idea was honored, I was constantly getting to talk to new people and having strangers welcome me to their conversations. There is something special about the R community as a whole (and R-Ladies!) where people are constantly encouraging and helping others.