Prioritizing data science work
Choosing between the many things you could work on
As a data scientist trying to support an organization, you must constantly decide what task you should be working on. You may be managing all sorts of tasks, such as:
-
tasks directly from stakeholders, like making a graph of sales over time for a big meeting tomorrow,
-
ideas that you personally think have a long-term benefit, like making a CLV model to predict high value customers, and
-
nebulous tasks from other parts of the business, like helping determine why customer retention seems to be down in one region.
It’s difficult to balance what’s the most important thing and what can be put on the back-burner, especially when you have multiple people requesting analyses from you. And often the work that people think is very important to them may not be important for the business as a whole. Often you are a more junior employee than the person making a data science request, making it further complicated to straight up say no, even if you can’t easily do it. All this creates an environment where the decision of what you work on can hugely influence the business, but also you are constrained in what to choose.
This is a topic I have personally struggled with in my career. When people from around the business come to me with questions about data, I almost always want to answer them and not to disappoint them. And usually I think the requests are interesting! However, trying to fulfill every request is unsustainable since the requests for answers are endless. Further, answering one question with data often leads to new questions, so fulfilling requests often creates additional work rather than lowering the amount of work left to do.
I’ve come to realize that when considering a possible analysis to do, there are two questions I want to answer first:
-
Does knowing the result of this analysis materially affect the company? and,
-
Is this innovative work that does something new for the business?
The answers to these two questions create four categories of very different types of work:
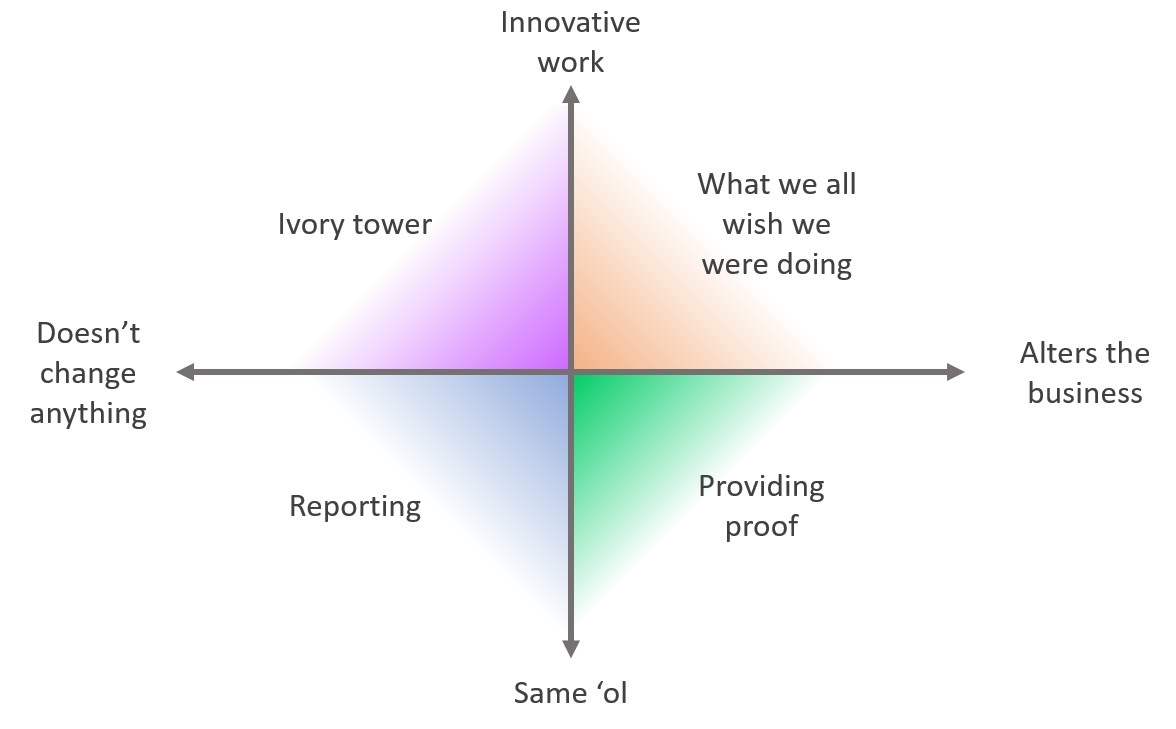
What we all wish we were doing (innovative and impactful) 😊
The ideal project is one that is both innovative work and alters the business. An example project would be creating a churn model that powers a marketing effort to win back customers. This is the sort of work that gets people into data science in the first place. Unfortunately, not many projects fall into this category ΓÇôit’s just hard to find groundbreaking places where you can really change a business. If you find a project in this category, do everything you can to get it off the ground.
Providing proof (not innovative but impactful) 🙂
These are the projects that aren’t innovative but alter the business, so by definition doing the work is valuable. Often this accounts to providing proof of a thing that everyone suspects is true ' it’s not particularly innovative but it will help out. For instance, people in a business may suspect that customers of certain demographic groups are less likely to return. Without proof that these hunches are true, people are unwilling to try and fix the marketing problem. If you can do some analyses that show the hypothesis is true, you can help move the business to a solution. This isn’t glamorous work, showing people things they already think to be true isn’t particularly wowing, but it is still useful. If you get this kind of work, try and do it.
The ivory tower (innovative but not impactful) 🤨
This is work that is innovative but not useful to the business, and it can be a huge sunk cost. These projects often come from within the data science team when people have ideas for new areas of modeling or analyses based on things that are methodologically interesting. An example project would be to try and use machine learning to segment customers without having an idea of what you would use the segments for. Without having a person from outside the data team who would have a use for the project, then the work probably won’t go anywhere. As a data scientist, it’s easy to feel that once you complete the project then people will be able to find a use for it. In practice, if you can’t immediately see a use for the project then business people probably won’t be able to either. Don’t get stuck working on these projects, since they will lead the data scientists to look like they aren’t contributing.
Reporting (neither innovative nor impactful) 😴
Work that doesn’t change anything and isn’t innovative usually ends up being reporting. This is supplying people with numbers and KPIs so they can monitor the business and ensure everything is running smoothly. Sometimes businesses will have good processes in place to review the reports and call out areas of opportunities. Other times these reports get created on a recurring basis but are never looked at. The best case scenario when doing reporting is that you can set up an automated process to quickly generate a report every time a new one is needed. The worst case scenario is that it is a heavily manual process every time you need to update it which becomes a drag on your overall ability to do work. As a data scientist the more you can avoid this becoming your job the better.
So as much as possible, prioritize the projects that affect the company and are innovative (the work we all wish we were doing). Otherwise, try and do the non-innovative but useful work of providing proof to people to help move the business along. Make sure you stay out of the ivory tower of doing interesting work that isn’t relevant to the business and that you avoid getting stuck doing only reporting. Good luck!
If you want a ton of ways to help grow a career in data science, check out the book Emily Robinson and I wrote: Build a Career in Data Science. We walk you through getting the skills you need the be a data scientist, finding your first job, then rising to senior levels.
