Hiring data scientists (part 3): interview questions
What I ask the candidates and why

If you got to this page as an aspiring data scientist looking for help with interviewing, check out the book by me and Emily Robinson: Build a Career in Data Science]
[This is part 3 in my series on hiring data scientists. If you want an overview of the skills I look for in candidates and the archetypes of candidates I see, start from the beginning]
When interviewing for a data scientist position, you need to quickly discover a lot about the candidate. An ideal data scientist’s skillset spans math/statistics, programming/databases, and business expertise. You need to probe each of these areas. You also want to find out if they are smart and get things done. I typically only have an hour to get a feel for how a candidate fares in each of those areas (followed a week or two later by a case study if I think the candidate has potential). As you can imagine, this makes for an intense interview.
When I first started interviewing candidates, I had no agenda. I would just talk to candidates for an hour and see where the conversation flowed. These interviews crashed and burned, so I made a standardized interview itinerary. Have a consistent agenda has been the single best thing for my interview process, so if you take anything from this article take that. My agenda is:
-
Introduction - I give them an overview of our company and my honest pitch on why our analytics team is great. I ask them about themselves to get a feel for their background, and ask them what they are looking for in a job. If I do this right, the candidate is excited for the rest of the interview.
-
Description of a recent problem - I want to hear about a project they’ve worked on recently. I ask them about how the project started, how they determined it was worth time and effort, their process, and their results. I also ask them about what they learned from the project. I gain a lot from answers to this question: if they can tell a narrative, how the problem related to the bigger picture, and how they tackled the hard work of doing something.
-
Technical deep dive - I check if they have skills in statistics, databases, programming, and interpreting data. The rest of the article will be about this, so get ready.
-
Ask them for questions - There are so many possible questions they could ask that if they don’t have any questions it’s a warning sign that they don’t think before they act. Not having questions could also be a sign that they don’t want the job (you can’t win ‘em all).
Technical questions
An interview has one purpose: to see if this person will be successful in the role you’re offering. From a technical standpoint, that means checking they have the prerequisite knowledge for the job. But people are dynamic creatures who learn and grow, and if a person is missing knowledge they can go read Stack Overflow and pick it up. So a technical interview shouldn’t be a test of exactly how much they know on a topic from memory. My interview questions are guided by three principles:
-
No trick questions or tests of cleverness. No question should require a candidate to get to an “a-hah” during the interview. You should only test them on things they should feel comfortable answering with their existing knowledge. A brain teaser question like “suppose you have a stack of pancakes in a random size order, how would you take a spatula and order them in the minimum number of moves?” doesn’t relate to what doing data science is in practice. Further, many strong candidates may not be able to answer this in seconds, because they need time to think and process. I secretly think these sorts of questions generally are there to make the interviewer feel clever for knowing the answer.
-
Only test on the basics. Given a particular area, I only ask questions at an introductory level. For instance, if asking a question about machine learn models, I would only ask about linear and logistic regressions and avoid asking about more advanced topics like Random Forests or boosting. The reason for this is that if they understand the basics they should be able to pick up the advanced topics on the job. Further, as you get into more advanced topics there is a higher likelihood that the candidate just never happened to deal with that topic. If they do know a lot of advanced materials, that will likely be noticeable in how they answer the basic questions.
-
Keep questions a discussion. I try to avoid questions where there is a single right answer, because the only information you get is if the candidate knows that exact answer or not. For instance, instead of asking “what is the difference between a left join and an inner join” I would ask “what are joins in SQL” and if they give a decent answer I would ask “what are some different types of joins?” The candidate may come up with a more interesting answer and I can probe into times they’ve had tricky joins to do.
For each area, I first ask them their familiarity with the topic. If they say they don’t have much, I skip it. I want to avoid having the candidate feel overwhelmed or frustrated by that topic, as that could jeopardize the rest of the interview.
Without further ado, here is the set of technical questions I ask and why:
Statistics
Easy question:
How would you explain a linear regression to a business executive?
This question tests if they have a good mental model of what a linear regression is, and if they can explain it in non-technical terms. The common way people mess it up by being too technical “suppose we have normally distributed errors in our dependent variables.” I’m looking for an answer that sounds something like “it’s a way of predicting a value as being proportional to some other values” along with a simple example.
Medium question:
What are some alternative models to a linear regression? Why are they better or worse?
If they understand data science, they should be able to explain other models and why they are better (Random Forest, SVM, Neural Nets, whatever). I don’t care about the quantity of models they know, just that their explanations are well thought out.
Databases
Easy question:
Given a table:
| Class | Student | Grade |
|---|---|---|
| Math | Jacqueline | 90 |
| Math | Heather | 98 |
| Languages | Amber | 100 |
| Languages | Owen | 90 |
| … | … | … |
Write a SQL query to create a table that shows, for each class, the value of the highest grade in the class.
If the person has any familiarity with SQL, they should recognize that they need to use a GROUP BY over Class and MAX(Grade). If they mess up the syntax a bit that’s fine, I’m confident they can pick it back up on the job. Even if they totally bomb the code but still mention aggregating by class I consider it a pass (but I won’t ask them the medium question).
To me, this question feels comically easy, and yet half of the people who list SQL on their resume are unable to do it.
Medium question:
Suppose I had the same table as the previous question, but instead for each class I want to find the name of the student who got the highest grade. Write a query to do that.
This question seems like it should be as easy as the previous one, but when you start working on it then it turns out more complicated. The solution requires either joining a temporary table or using a subquery. A particularly astute interviewee will notice the question doesn’t tell you what to do in the case of ties in highest grade.
Programming
Easy/medium question:
In pseudo-code or whatever language you would like: write a program that prints the numbers from 1 to 100. But for multiples of three print “Fizz” instead of the number and for the multiples of five print “Buzz”. For numbers which are multiples of both three and five print “FizzBuzz”.
Yes the classic FizzBuzz, known as the question that any capable software developer should be able to answer. You can find lots of writing on it, including a great enterprise version. Since data scientists are weaker programmers than software developers, this question is excellent for interviewing.
When a person is working on their problem, I listen to how they reason. If they make statements like “hmm, well I should probably look at each number so I’ll use a for loop” or “I’ll handle this by using an if-else statement–oh! I guess I need to check for FizzBuzz first since both the other conditions apply” that’s a great sign. Provided they stumble to any working answer I consider this an easy pass.
To pass at the medium level, I ask them to improve their code by making so that the number/word pairs are part of the input, and I could pass an arbitrary amount of them (for instance I could add that 17 prints Jazz). A good-enough-for-data-science programmer should be able to do this.
I also ask them if they’ve heard of this problem before, since if they’ve read up on software development they likely would have heard of it already. So far only one person I have ever interviewed has 🤷♀️.
Interpreting data
Easy/Medium question:
A company selling a competitor to Microsoft Office is testing their marketing by sending out two different sets of emails. One set contains business related content, and one contains consumer related content. We are interested in how each campaign performed; did one do better at getting people to click-through? Below is a selection of graphs on the two email campaigns. The bottom two graphs have the same data as the top two, only bucketed by the amount the customer has spent with the company the year before the emails were sent. Which campaign did better?
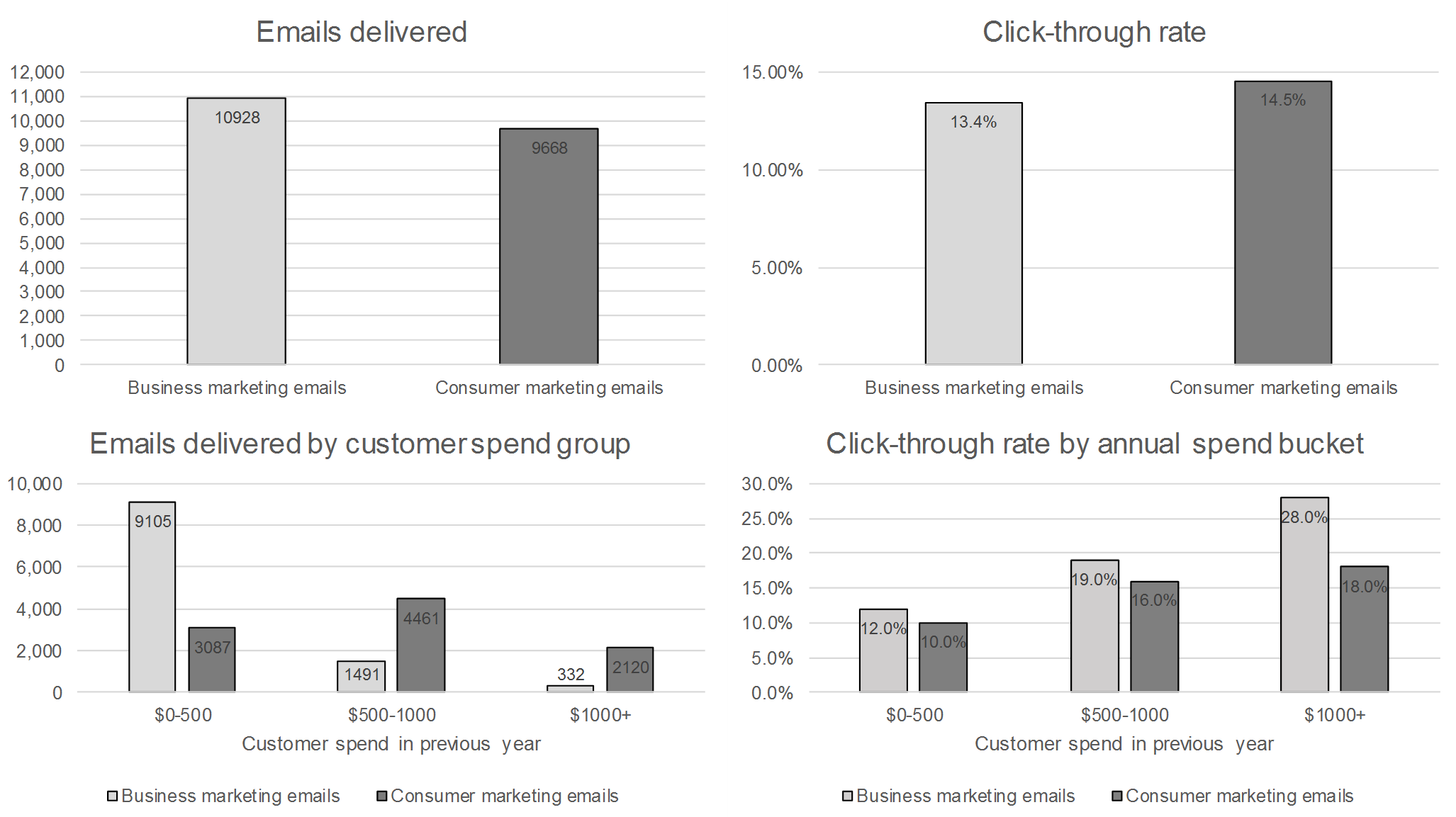
The point of this question is to understand how they interpret data. A strong data scientist should be able to take a set of graphs and explain what is happening within the data and what that means. As a data scientist, this is probably the single most important activity you do. I think this is something people don’t test enough of when interviewing data scientists.
For these particular sets of graphs, if you look in aggregate the consumer marketing emails had a higher click-through rate, however when you split into the different customer spend buckets, the business emails do better. For some reason, most of the business emails went to the low value customers with lower click rates, and so while in aggregate the business emails did worse, when you account for spend they did better.
If the candidate really struggles with this question it’s likely I will pass on them. The people who tend to struggle on this are the ones who have spent more of their careers making graphs than thinking about what the graphs mean. If you’re following along at home, you may notice that this question is an instance of Simpson’s Paradox.
By the end of these questions, I have a good feel for where the candidate falls on the math/stats and programming/databases skillsets of data science. I also have a good feel for if they are smart or not. Unfortunately, I don’t know their level of business expertise nor their ability to get things done. To find those out I use a case study, which is discussed in the fourth and final part of my series on hiring data scientists.
If you want a ton of ways to help grow a career in data science, check out the book Emily Robinson and I wrote: Build a Career in Data Science. We walk you through getting the skills you need the be a data scientist, finding your first job, then rising to senior levels.
